如何从具有体育结果的数据集中平均历史统计数据?
湾
我有网球数据集,这是头部:
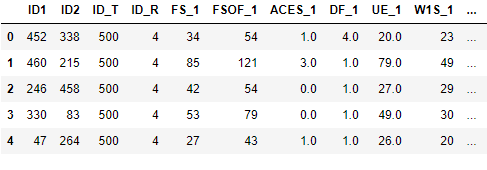
现在我想平均给定 ID1 的 FS_1。换句话说,我想从这个数据集中的数据中得到所有球员的平均一发百分比。并且所有玩家都会出现多次。
我知道我可以这样做来获得一个字段的平均值;
def mean(arr):
return sum(arr) / len(arr)
mean(dataset['FS_1'])
但我如何获得特定球员的平均水平?
卡波
Pandas groupby方法应该可以解决问题:
df.groupby(['ID1']).mean()['FS_1']
本文收集自互联网,转载请注明来源。
如有侵权,请联系[email protected] 删除。
编辑于
相关文章
Related 相关文章
- 1
体育统计数据的SQL表设计
- 2
MYSQL 平均日统计数据
- 3
此SQL模式是否适合存储体育数据和统计数据?
- 4
如何使用 Shiny 获得基本统计数据?Tapply 错误:参数必须具有相同的长度”
- 5
如何将统计数据(* .sta)导入R
- 6
如何创建汇总统计数据框架?
- 7
iperf如何计算网络统计数据
- 8
如何将统计数据(* .sta)导入R
- 9
iperf如何计算网络统计数据
- 10
如何观察整个会话的游戏统计数据?
- 11
从表创建统计数据
- 12
令人毛骨悚然的统计数据
- 13
gnuplot多列的统计数据
- 14
Docker统计数据100%内存
- 15
每天选择并统计数据
- 16
来自吉西的统计数据
- 17
良好的统计数据集成
- 18
统计数据处理
- 19
MongoDB 的 30 天统计数据
- 20
统计数据:估算投资组合的每月加权平均值
- 21
如何保持与仓库同步的回购统计和用户统计数据库?
- 22
如何保持与仓库同步的回购统计和用户统计数据库?
- 23
从数据库获取每月统计数据的优雅方式(没有动态 SQL)?
- 24
统计数据中的流入/流出计数
- 25
统计数据框中的特定数据并显示
- 26
Darts 数据库以保存统计数据
- 27
通过使用Google表格中具有多个数量的单个值来计算数据集的统计数据
- 28
使用具有 NA 的数据框中的多个类别按行计算斜率和相关统计数据
- 29
保存Jenkins工作历史/成功率统计数据超过6个月的最佳方法?
我来说两句